시작하며)
정말 오랫만이네요.. 강좌를 쓰는게...
그동안 있었던 일을 모두 열거하긴 너무 힘들것 같습니다. 따로 DEV.WON 썰에 쓰도록 하지요..
요즘 화두가 되고 있는 클라우드 컴퓨팅환경을 지원하기 위한 MS 사의 Azure를 보고 있는데. 가격정책이 그리 나쁘진 않을꺼 같단 생각이 듭니다.
오늘은 데이터베이스의 튜닝에 대해서 간략히 설명해 보려합니다.
사실 DB튜닝의 정답이 어디있겠고 끝이 어디 있겠습니까..그리고 쉬운작업도 분명히 아니겠지요.
이 강좌의 목적은 초절정 튜닝 고수가 되어 DB컨설팅을 다니며 화려한 스포트 라이트를 받자는게 아닙니다.
다만 개발자로써 DBA한테 무시 받지 않을정도로만, 또는 DBA가 없는 회사에서 독고다이 DB를 관리하셔야 하는 분이거나,
아님 우리 회사 시스템이 너무 느려 터져서 본인이 손수 고쳐 보겠다고 하시는 분들에 한해서 입니다.
전문 DBA 로써 강좌를 작성한것이 아니니, 강좌의 퀄리티를 기대하진 마세요..
하지만 난 아무리 DB튜닝에 대해서 공부해 봐도 모르겠다는 분들을 위하여 최대한 재믿고 쉽게 쓰도록 노력해보겠습니다.
마지막으로 이 강좌는 MS-sQL 2005 기반에서 작성되었습니다.
튜닝을 위한 사전 지식)
튜닝을 하려면 몇가지 바탕이 되는 기술이 필요합니다.
아주 간략히 얘기해보죠..
[1] PROCEDURE 의 쿼리 처리 과정과 캐쉬에 대한 이해
mssql의 쿼리처리 과정은 다음 5단계를 거친다.
1. 구문 분석 (Parsing)
2. 표준화 (Standardization)
3. 최적화 (Optimization)
4. 컴파일 (Compilation)
5. 실행 (Execute)
매번 저 단계를 거치는 것은 부하가 크므로 메모리에 캐시하게 되며
syscacheobjects 테이블을 보면 그 캐시에 저장된 쿼리 내역을 알 수 있다.
아래처럼 간단하게 호출을 한다.
select * from sys.syscacheobjects;

<v:f eqn="if lineDrawn pixelLineWidth 0"></v:f><v:f eqn="sum @0 1 0"></v:f><v:f eqn="sum 0 0 @1"></v:f><v:f eqn="prod @2 1 2"></v:f><v:f eqn="prod @3 21600 pixelWidth"></v:f><v:f eqn="prod @3 21600 pixelHeight"></v:f><v:f eqn="sum @0 0 1"></v:f><v:f eqn="prod @6 1 2"></v:f><v:f eqn="prod @7 21600 pixelWidth"></v:f><v:f eqn="sum @8 21600 0"></v:f><v:f eqn="prod @7 21600 pixelHeight"></v:f><v:f eqn="sum @10 21600 0"></v:f><o:lock aspectratio="t" v:ext="edit"></o:lock>
(자세한 컬럼은 여기를 참조 한다. http://msdn.microsoft.com/ko-kr/library/ms187815.aspx)
dbcc freeproccache; --프로시저 캐시에서 모든 요소를 제거하는 구문
실행계획 보는 방법 , 인덱스 스캔 vs 테이블 스캔

(쿼리 선택후 Ctrl + L 또는 위의 아이콘을 클릭하면 예상 실행 계획을 볼수 있다)
이 탭을 선택하여 내역을 보도록 하자. 탭을 선택하게 되면, 두 개의 아이콘이 보이게 된다. 여기서 오른쪽 아이콘에 마우스를 가져간 다음, 1~2초간 머무르면 다음의 그림과 같이 팝업이 뜨게 된다.
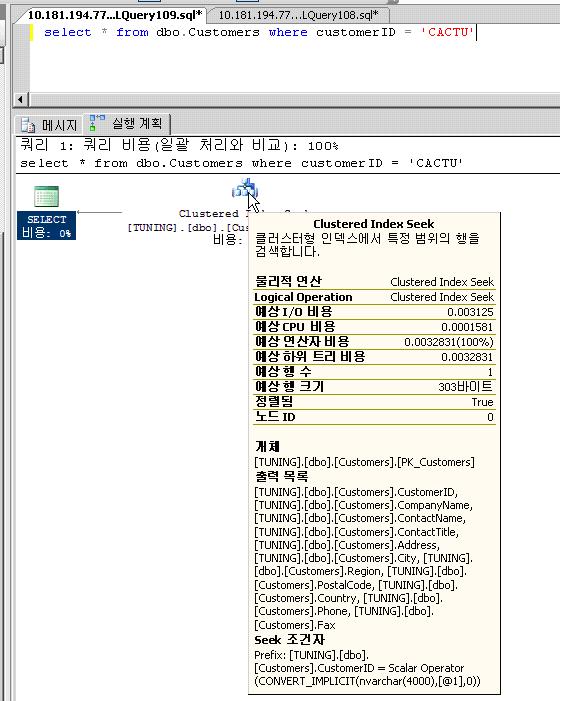
내용을 보면, 여러 가지의 항목이 숫자 값으로 표현이 되고 있다. 각 항목들은 쿼리를 수행할 때 SQL Server가 내부적으로 어떠한 작업을 수행하였는지를 통계적인 수치로 보여주는 것이다. 우선 물리적인 연산과 논리적인 연산을 보면, Clustered Index Seek라고 되어 있다. 다음의 행 개수 는 수행된 쿼리에 의해서 반환된 행의 개수를 말한다.
I/O비용은 해당 작업, 즉 아이콘이 표시하고 있는 내부적인 작업에 의해서, SQL Server가 설치된 서버의 하드디스크에 대해서 물리적으로 읽기작업이 일어난 비용을 말한다. SQL Server가 데이터를 반환하는데 있어서, 가장 많은 시간을 필요로 하는 부분이 바로 물리적인 하드 디스크로부터 데이터를 읽어 들이는 것이기 때문에, 좀 더 빨리 데이터를 반환하기 위해서는 SQL Server가 하드 디스크로부터 데이터를 읽어 들이는 작업, 즉 I/O의 횟수를 줄이는 것이 필요하게 된다. 때문에 I/O 비용에 나타난 값이 작으면 작을수록 데이터를 빠르게 반환하게 되며, 효율적인 쿼리문을 작성한 것이라고 할 수 있다.
또한 비용 은 쿼리문의 실행에 필요한 비용을 말하는 것이다. 즉 쿼리를 수행하는 데 소요되는 비용을 말한다. 따라서 이 수치 역시 작을수록, 효율적인 쿼리가 수행되는 것이다.
자 이제 방금전 언급되었던 물리적 연산/논리적 연산에서 나왔던 clustered index seek 에 대해서 알아볼 필요가 있다. 이말인 즉슨, 테이블에 있는 인덱스를 이용하여 쿼리를 수행하였다는 것을 말한다. 왜 인덱스를 이용하면 테이블의 일부만을 검색하게 될까? 테이블의 일부만을 검색하고도, 정확한 데이터를 반환할 수 있을까? 그렇다. 테이블의 일부만을 읽어서도 정확하게 데이터를 반환할 수 있다. 이것이 바로 인덱스의 장점이다.
사실 위의 쿼리 select * from dbo.Customers where customerID = 'CACTU'
에는 눈치챈 독자도 있겠지만 customerID에 index가 걸려있다. 그래서 당연히 index seek를 할수 있었던 것이다.
자, 그렇다면 해당 인덱스를 drop해 볼까나..하지만 테이블 생성시 primary key clustered 로 생성하여 drop이 되지 않으니, 똑 같은 스키마 구조로 인덱스만 제거하여 새롭게 테이블을 생성하였다.(customers_have_not_index)
이제 두 번째 문장을 실행하여 첫 번째 문장의 실행 계획과 비교하여 보도록 하자.
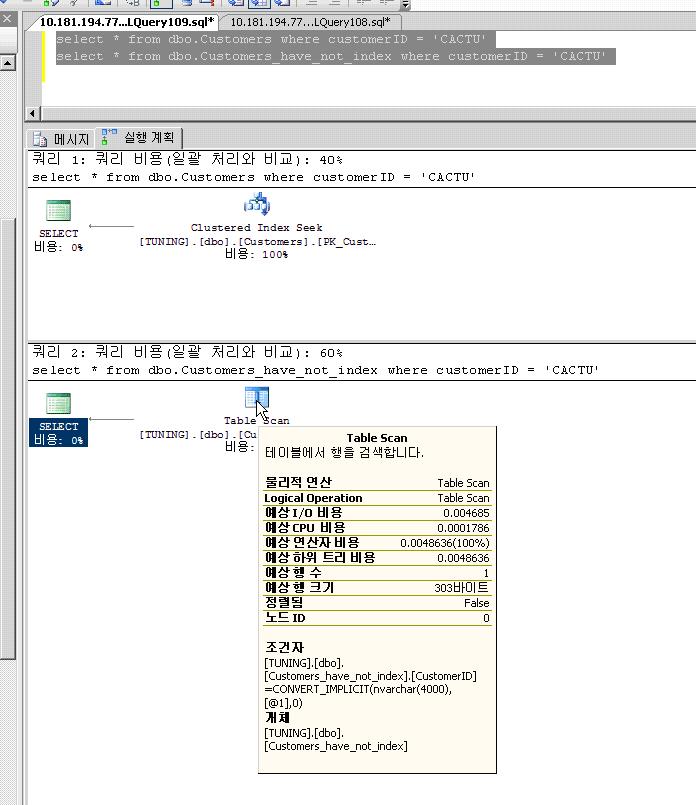

우선 I/O 비용을 비교하여 보도록 하자. 각각 0.003125와 0.004685로 수치상에서 격차를 보이고 있음을 알 수 있다. 또한 쿼리의 연산자 비용과 하위 트리 비용에서도 차이가 나느것을 알수 있다.
또한 매우 중요한 사실인데 위의 그림에서 정렬됨을 보면 customers 테이블의 실행 계획은 true이다. 하지만 customers_have_not_index 에서는 false인 것을 알수 있다.
그 이유는 clustered index는 내부적으로 인덱스 생성시 인덱스 데이터를 정렬 하는 특징을 가지고 있기 때문이다.
정리를 좀 해볼까.
두번째 테이블은 table scan이다. 앞서 첫번째 테이블은 index scan이다.
Index scan : 색인을 가지고 데이터를 조회해온다(첫번째 테이블의 실행계획)
Table scan : 색인이 없는 컬럼으로 조회를 하는 경우, 원하는 레코드 의 값을 가져오기 위해 처음부터 끝까지 하나하나 읽어가면서 원하는 정보를 찾는다. ( full scan이라고도 함)
이렇게 인덱스가 설정된 테이블과 인덱스가 설정되지 않은 테이블에 대한 데이터 반환 요구 시, 필요한 비용만을 보아도 성능의 차이를 느낄 수 있다. 인덱스가 설정된 테이블의 경우에는 인덱스를 이용하여 데이터가 있는 위치를 쉽게 찾을 수 있기 때문에, 필요한 비용도 작게 나타났다. 반면에 테이블에 인덱스가 설정되어 있지 않은 경우에는, 테이블 전체를 읽는 작업을 수행하기 때문에 그 만큼 많은 비용을 필요로 하게 되고 데이터가 반환되는 시간까지도 늦어지게 되는 것이다.
[2] 인덱스에 대한 이해]
인덱스는 다음과 같은 구분 기준에 따라 나눌수 있다
1) 구조적인 기준
n Clustered Index
n Non-clustered Index
2) 인덱스 구성 컬럼의 수
u Single-Column Index
u Composite Index
3) 유일값 유무에 따른 기준
u Unique Index
u Non-unique Index
[2-1] 차례 와 색인
인덱스를 이해하기 위해서는 차례와 색인을 먼저 이해 하는 것이 중요하다.
우리는 데이터 베이스 관련 서적 한권쯤은 가지고 있을 것이다. 그 책의 맨 앞장을 보라!
저자 소개 및 머리말이 지나가고 ( 근데 대부분 머리말에 보면 마지막에 사랑하는 가족에게 감사하다는 말을 <st1:personname w:st="on" o:ls="trans">남기전</st1:personname>에 묵묵히 몇일의 원고 마감 밤샘작업을 묵묵히 지켜봐준.. 이라는 문구는 자주 들어본거 같다.. 아마도 저자분들 모두 힘들게 집필하신 것이 틀림없다.ㅜ) 다음 장을 넘겨 보면 차례가 나오는 것이 대부분이다.
차례의 특징이 몬가. 이 책이 1페이지부터 1000페이지까지 있다면. 1페이지부터 마지막 페이지까지 차례대로 중요한 부분 부분에 제목과 페이지 숫자가 적혀있다.
1. 데이터 베이수 개론 --------- .1
1-1 데이터 베이수 의 개념 -------- .2
1-2 데이터 베이수 의 역사 -------- .4
2. 데이터 베이수 SQL -------- .21
2-1 ANSI SQL 이란 -------- .22
중략..
모 대략 이런식이다.
차례의 특징은 독자들은 서적을 처음부터 끝까지 뒤지지 않아도, 찾고자 하는 내용을 찾을수 있다.(순서대로 구성되어 있는 제목과 소제목들)
이제 서적의 맨 마지막으로 가 보도록 하자.
맨 마지막 페이지는 가격과 출판일시등이 나와있다. 맨마지막 바로 전 페이지를 보자. ㅜ
어라? 색인 또는 index 이라는 제목으로 약 3페이지 정도 걸쳐서, 한글의 자모순서 또는 알파벳 순으로 해당 내용이 어디에서 설명이 되고 있는지를 페이지의 번호와 함께 제공이 되고 있다. 이게 색인이다.
- 클러스터된 인덱스
먼저 클러스터된 인덱스를 살펴보도록 하자. 클러스터된 인덱스는 설명한 것과 같이 인덱스로 설정된 컬럼에 있는 데이터의 순서대로, 하드 디스크 상에 물리적으로 저장되는 것을 말한다. 바로 위에서 말한 "차례"에 해당한다는 것을 의미한다.
- 차례
- 테이블 당 하나만 설정가능
- 클러스터 되지 않은 인덱스보다 빠르다
- 유니크 인덱스로 설정된다
- 데이터 입력 시, 비교적 느리다.
- 범위에 의한 쿼리
클러스터된 인덱스는 클러스터 되지 않은 인덱스를 설정한 경우보다도 더 빨리 데이터를 반환할 수 있다. 이는 실제로 데이터가 순서대로 저장이 되기 때문에, 물리적인 하드 디스크 공간에 여기저기 분포하고 있는 데이터를 찾아서 반환하지 않고, 순서대로 데이터를 읽어오기만 하면 되기 때문이다.
이렇게 클러스터 인덱스는 데이터를 사전식으로 저장하기 때문에, 테이블 당 하나만을 설정할 수 있다.
(엄연히 말하면 클러스터드 인덱스로 설정된 컬럼의 데이터는 사전식 순서대로 물리적인 공간에 저장되는 것은 아니다. 실제로 그렇게 되면 서버측에 부하를 초래 한다. 만약 1억건의 데이터가 입력된 테이블에서 클러스터드 된 인덱스의 순서에 의해 첫번째 순서로 저장되어야 하는 데이터가 입력되면.. 기존 데이터는 차례로 뒤로 밀려야 하며, 이러한 작업은 엄청한 부하를 초래 하기 마련이다. 그렇기 때문에 내부적으로는 페이지라는 작은 단위로 나뉘어 데이터가 저장된다. 이때 각 페이지 간의 다음에 위치하게될 페이지가 어디에 저장되는지에 대한 정보가 필요하다. 이 정보를 페이지 체인(page chain) 이라고 부르며, 실제로 데이터가 순서대로 저장된다는 의미는 이 페이지 체인이 순서대로 연결된다는 것을 뜻한다.)
- 클러스터 되지 않은 인덱스
다음에는 클러스터 되지 않은 인덱스를 살펴보도록 하자.
- 목차
- 물리적으로 순서에 따라서 데이터가 저장되지 않는다
- 데이터 반환 시, 클러스터된 인덱스와 비교하여 느린 편
- 데이터 입력, 수정, 삭제 시, 클러스터 인덱스에 비하여 빠른 편
- 테이블 당 249개까지 설정이 가능
- 적은 범위의 데이터에서 특정 데이터를 반환하는 쿼리
클러스터 되지 않은 인덱스는 앞서 설명을 하였던 "목차"와 같은 기능을 가지고 있다. 즉, 데이터가 순서대로 저장이 되어 있지는 않지만, 어디에 저장이 되어 있다는 정보를 데이터가 저장되는 저장장소와는 별도의 공간에 따로 저장을 하는 것을 말한다.
클러스터 되지 않은 인덱스는 클러스터된 인덱스와는 달리, 물리적으로 데이터가 사전식 순서에 의해서 저장되지 않는다. 따라서 데이터를 반환하는데 있어서는 클러스터된 인덱스보다는 느리지만, 반대로 데이터의 입력, 수정, 삭제작업에 대한 성능은 클러스터된 인덱스에 비하여 빠른 편이다.
이렇게 클러스터 되지 않은 인덱스는 물리적으로 서버의 하드 디스크에 아무런 변화도 주지 않기 때문에, 테이블 당 249개의 클러스터 되지 않은 인덱스를 설정할 수 있다. 클러스터 되지 않은 인덱스는 클러스터된 인덱스와는 달리, "아이디가 100인 값을 반환하라"와 같이 조건으로 하나의 값만이 반환되는 쿼리에 사용하는 것이 성능에 도움이 된다. 또한 클러스터 되지 않은 인덱스는 선택성(Selectivity)가 높은 경우에는 그 성능을 십분 발휘할 수 있게 되기 때문에, 클러스터 되지 않은 인덱스를 선정하는 경우에는 선택성을 고려하여 선정하기 바란다.
Clustered index와 non Clustered index의 비교
| Clustered Index | Nonclustered Index |
최대 Index 수 | 1 | 249 |
Index 지정에 따른 크기 | Table 크기의 1~5% | Table 크기의 10~20% |
조회성능 | 빠름 | Clustered Index보다 느림 |
Data 수정 | Nonclustered Index보다 느림 | 빠름 |
사용 | 영역을 지정한 조회 | 하나의 값을 반환하는 조회 |
[2-2] 단일 컬럼 인덱스 & 복합 컬럼 인덱스
인덱스는 인덱스를 구성하는 컬럼의 수에 따라서도 나눌 수 있다. 앞서 설명을 드린 예에서는 하나의 컬럼만으로 인덱스를 설정하였다. 이를 단일 컬럼 인덱스라고 한다. 반대로 하나 이상의 컬럼으로 인덱스를 설정하는 경우에는 복합 컬럼 인덱스(Composite Index)라고 한다. 복합 인덱스는 쿼리가 이루어질 때, 하나 이상의 컬럼에 대해서 자주 쿼리가 발생되는 경우에 유용하게 사용될 수 있다. 즉 복합 컬럼 인덱스는 T-SQL 구문을 이용하여 쿼리를 작성하는 경우, WHERE절에서 자주 사용되는 컬럼들을 복합 컬럼 인덱스로 작성하면, 쿼리의 성능을 향상시키는데 많은 도움을 주게 된다.
단, 복합 컬럼 인덱스의 경우 인덱스 생성시 컬럼의 순서가 중요하다.
예를들어, 아래와 같이 복합 인덱스를 생성한다면
CREATE INDEX ix_companyName_contactTitle ON customers(companyName , contactTitle)
첫번째 companyName 가 먼저 정렬되고 두번째로 contractTitle이 정렬된다. 즉 contactTitle로 where 쿼리 조회시 index seek가 일어나지 않을 수 있다.
따라서 복합 컬럼 인덱스의 컬럼에서 첫번째 컬럼으로 작성된 컬럼을 조건절에서 이용하여, 가능하면 데이터 중에서 찾을 테이터의 범위를 줄여나가도록 하는 것이 좋다.
이와 같이 복합 컬럼 인덱스를 사용하면, 인덱스 페이지에 해당 컬럼들의 데이터를 가지고 있게 되기 때문에 보다 빠른 검색을 할 수 있게 된다. 하지만 복합 컬럼 인덱스가 장점만 가지고 있는 것은 아니다. 만약 복합 컬럼 인덱스로 설정된 컬럼의 크기가 크다면, 그 컬럼들의 크기만큼 인덱스 페이지를 작성하여야 하기 때문에 저장공간의 낭비를 초래할 수도 있다. 또한 데이터가 입력, 수정, 삭제되는 작업이 발생할 때마다, 그 크기만큼의 인덱스 페이지를 수정하는 작업을 하여야 하기 때문에, 단일 컬럼 인덱스보다는 더 많은 시간과 비용이 필요로 하게 된다.
[2-3] 유일값 유무에 따른 기준 : 유니크 인덱스 & 중복 값 인덱스
다음에는 유니크 인덱스와 중복 값 인덱스이다. 이미 눈치가 빠른 독자들은 이 인덱스들이 어떠한 성격을 가지는지 눈치 챘을 것이다. 그렇다 유니크 인덱스와 중복 값 인덱스는, 인덱스로 설정된 컬럼에 데이터가 중복된 값을 가지는지, 아니면 유일값을 가지는 컬럼인지에 따라서 분류된 것이다.
클러스터된 인덱스는 가능하면 유니크 인덱스로 설정할 것을 권장한다. SQL Server 2000에서 클러스터된 인덱스를 설정할 때, 유니크 인덱스로 지정하지 않는다면 SQL Server는 자동으로 해당 테이블에 대해서 각 열(Row)마다 Uniqueidentifier 값을 추가하게 된다. 이는 각 열(Row)들을 유일하게 지정하여, 중복되는 값을 제거하기 위한 것이다. 따라서 가능하면 클러스터된 인덱스를 지정하면서, 유니크 인덱스를 지정하는 것이 좋다.
간략히 얘기한다고 했으나 이제 보니 양이 적지 않았다.
사전 배경 지식으로써 인덱스만 가지고 얘기했는데도 말이다. 사실 이렇듯 튜닝을 하기 위해서는 알아야 할것이 너무 많다. (당연한 소리겠지만)
사실 필자의 경험상으로는 대부분의 속도상의 이슈가 되는 DB상의 문제중 상당수는 SQL 실행계획에 문제가 있어서 이를 해결하면 대부분이 해결되었던 것이 많다. 그래서 인덱스만이라도 설명은 꼭하려고 했던것이다.
자 다음은, 실제로 이 인덱스를 가지고 데모 성격으로 실제 유사하게 튜닝을 해보도록 하자.
[3] INDEX SEEK 이해하기
SEEK의 사전적 뜻은 ~을 찾다. ~을 구하다 정도가 되겠다. 즉 index를 찾겠다는건데 이때
Index scan 처럼 쭈욱~ 처음부터 끝까지 찾는게 아니라 콕콕 찝어서 원하는걸 바로 바로 찾아간다고 하는것에 좀 차이가 있다(물론 seek 가 훨 빠르다.)
INDEX SEEK는 클러스터드 유무에 따라서, 다음으로 분류된다.
1. Clustered Index Seek
2. Index Seek
Index 종류에 따른 seek를 나눈것이다.
첨언을 하자면 Non-Clustered Index는 Dense Index이고 Secondary index 성격을 띄고 있다.
쉽게 말하면 Non-Clustered는 B트리 구조가 밀집되고 빡빡한 느낌이 있다는것인데 무슨말인지 지금 당장 이해 하지 않아도 좋다.
자 Index Seek를 하는 하부 알고리즘을 이해해 보자.
모든지 그렇지만 해당 시스템에서의 핵심 원리를 알아야 다른 응용이 가능하고 확장이 가능하다.
Index seek를 이해 못하면서 하는 튜닝은 튜닝이 아니다. 원리와 동작 방식을 이해 하지 못하고 어떻게 속도 튜닝을 하겠다는 말이겠는가. 그만큼 강조를 하니 꼭 이해 해 주길 바란다.
자, [CodeMaster] 라는 테이블이 있다고 가정하자.
그리고 해당 테이블에는 클러스터드 인덱스가 없다고 가정해보자.
다음과 같은 SQL문장이 있다.
SELECT * FROM CodeMaster
WHERE code_1 IN (‘B105’ , ‘C101’)
그리고 code_1 라는 컬럼에는 Non-Clustered Index가 생성되어 있다고 가정해 보자.
Non-Clustered Index의 Data Page는 Heap 이다.(Heap은 클러스터 인덱스가 없는 상태를 말한다.)
(첨언이지만 거의 대부분의 DBMS는 데이터 입출력 은 Byte 단위로 일어나지 않는다. 각각의 DBMS 플랫폼마다 최소한의 입/출력 단위가 정해져 있는데 Oracle은 이러한 입/출력 의 단위를 직접 세팅 할수 있으나 MS-SQL Server는 8KB fix 이다. 이말은 SQL Server에서는1Byte를 읽기 위해서는 어쩔수없이 8KB를 읽어야 한다는 뜻이다.
Index seek를 설명하기 위해서 아래 그림과 같이 인덱스 구조를 표현해보았다.
MS-SQL이라면 아래 그림의 Index Page, Data Page는 모두 8KB이다.
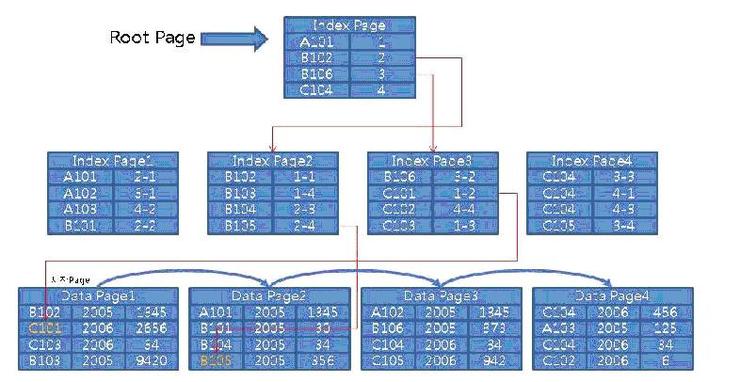
자, MS-SQL 제품이라고 가정을 해보고 Index Seek의 절차를 살펴보자.
자 위의 쿼리가 동작을 하면 모르긴 몰라도 제일 처음 할 것은 ‘B105’ 라는 코드를 찾을려고 할것이다.
그런데 code_1 컬럼이 인덱스가 생성되어 있으니 인덱스를 이용하여 데이터를 찾으려 할것이다.
1. 제일먼저 Root Page를 읽어서 다음에 접근할 Index Page Number를 찾는다. 즉, ‘B102’로 시작되는 2번째 index page에는 ‘B102’ ~ ‘B105’ 까지 있음을 Root Page를 통해 알수 있다.
2. Index Depth가 2이므로 중간노드가 Leaf Node이다. Leaf Index Page에서 row locator가 가르키는 데이터 페이지의 해당 row를 읽는다.
‘C101’도 동일하다.
이해가 되지 않는 독자분들은 다른 책을 더 참고하는 것이 좋을것이다. 본 강좌에서는 아주 간략히 설명하였기 때문에 이해에 어려움이 있을수 있다.
Anyway, 위의 과정에서 총 몇번의 Page에 접근하였는가를 살펴보자.
‘B105’ 를 찾기 위하여 3Page(Index Page 2번 + Data Page 1번) 를 읽었고, ‘C101’도 마찬가지로 3번이다.
위의 Seek 의 중요한 전제는 바로 unique index일 경우라는 것이다.!
만약 위의 인덱스가 non-unique index였다면 얘기는 달라진다.
Non-unique index 라면 현재 위치 바로 다음의 데이터 값이 현재값과 같을수도 있으므로 ‘B105’ 다음 값을 계속 읽으면서 ‘B105’가 아닌 값이 나올 때 까지 순차적으로 읽어야 할것이다.
반면, Unique Index라면 현재 값이 ‘B105’이면 다음 값은 다른 값이 분명하므로 아예 다음 값을 읽지도 않는다.
그리므로 확실히 unique한 데이터의 값을 가지는 컬럼에는 unique index를 걸어주는 것이 성능상 이점이 많다.
그럼 어느게 best way인지 감이 올 것 같은데, 안타깝게도 계속 강조했지만 그때 그때 상황에 따라 다르다는것이다.
즉, 인덱스가 만병통치약은 아니라는것인데,
실제로 인덱스를 이용한 접근 방식은 Page access depth가 깊어진다.
즉, 입/출력 cost가 상승하게 된다. 또한 index seek보다 차라리 어떨때는 Data Page를 순차적으로 scan하여 데이터를 찾는 것이 더 빠를때도 많다. 그 차이점은 바로 데이터 로우의 개수다.
이러한 이유로 많은 권고 사항 및 DB 관련 책에서는 적은 수의 Row를 가지는 테이블에는 인덱스 생성이 오히려 독이 될수 있다고 말한다. 하지만 시간이 지나면서 옵티마이저도 발전을 거듭해 왔다.
그래서 옵티마이저가 데이터 Row 수를 판단하여 인덱스가 있음에도 Seek를 수행하지 않고 바로 Table Scan으로 수행하는 경우가 빈번하다. 이게 바로 Cost Based Optimizer의 강점이자 똑똑한 점이다.
여러분 입장에서는 index Seek를 할지 Full Scan으로 풀지에 대한 고민은 Index 를 이용할 때 와 Table Full Scan을 할때의 Disk I/O 와CPU비용들을 고려하는 것이 가장 좋은 방법이 아닐까 생각든다.
인덱스 가지고만 튜닝해보기)
자, 지금까지 언급한것만 가지고 실제로 튜닝을 해보도록 하겠다. 본 강좌 작성중 어려웠던 점은 실제로 속도상의 문제가 있는 DB의 데이터 상태를 만들어 놓는것이었다. 실제로 통계정보의 정확도도 떨어뜨려야 좀더 실전과 유사한 상황을 만들겠지만.. 어쨌든 문제가 되는(튜닝의 소지가 다분한) DB의 예제상태로 만드는 것은 다소 난해했다.
[1] Sort를 제거하라!
자, 모르긴 몰라도 DB의 SQL 문장에 대한 처리는 간결하고 서버에 부담을 주지 말아야 한다는 것은 모두다 알고 있는 사실이다. DB입장에서 데이터 조회는 최소화 되어야 한다.
실제 어플리케이션에서 상당수 차지하고 있는 기능이 있다. 바로 정렬기능.
XX번가 쇼핑몰이나 x션, Gx켓 등의 쇼핑몰들에 보면 모가 있는가?
가격순/정렬순/판매순…
그러면 여러분의 머리속에는 자연스럽게 ORDER BY 절이 떠오른다. 이걸가지고 얘기해보도록 하자.
(본 예제에서 필자가 별다른 index create 구문이 없다면 해당 테이블에는 인덱스가 없다고 생각해 주길 바란다.)
그리고 예를 들 테이블에 데이터양에는 신경을 덜 써주길 바란다. 어차피 데이터양에 따라서 튜닝의 접근 시작부터가 달라지고 그때그때 대처해야하는 방식이 다르다. 그저 normal 한 상태정도라고 가정하고 봐주길 바란다. 그리고 테이블의 스키마 구조는 상식적인 수준이고 주문관련 테이블들도 구성하였으니 크게 어려움은 없을거라 믿는다.
아래 문장은 평범한 order by 절이 있는 SQL 이다.
자 우리가 눈여겨 보아야 할 것은 실행계획.!
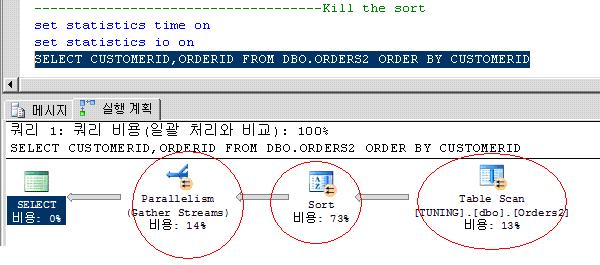
실제로 상당히 퍼포먼스가 떨어지는 실행계획이다. 물론 대부분의 상황이 그렇지만 위의 테이블의 데이터 레코드가 모 10개 100개 이런건 논의의 대상이 아니다.
만약 10만개면? 100만개면 어떻게 될까.. 문제가 심각해질것이다. 또한 위의 쿼리를 수행하기 위해서 DBMS는 메모리에 올릴것이고(query workspace) 그러다 메모리가 부족해지면 디스크 IO를 무쟈게 발생시키며 물리적 worktable을 만들어 작업을 수행할것이다. 동시 접속자가 많은 페이지에서 위의 문제가 되는 SQL를 지속적으로 호출하는 상황이라면? 불을 보듯 뻔하다. 이 사이트 왜이리 느려? 서버 증설하자! 이런 식의 ..
자, 또 잡담이 길어졌다.
위의 3개의 동그라미가 시사하는 바가 있다.
우선 순서대로 분석을 해보자.
1. table scan
2. sort
3. Parallelism
의 순서대로 수행이 되었다.
자 우리는 이제 각각이 의미하는 바를 이해해야 하고 어떤상황에 해당작업이 이루어지며, 더 나아가 데이터 양의 상태와 데이터 조각상태, 통계상태 에 따라 천차만별의 실행계획을 내밷어 낸다는 것을 느껴야 하고, 본인의 생각자체가 optimizer가 생각하는 거와 유사하게 사고가 이루어져야 한다.
그럼 왜 위의 3개의 처리가 이루어졌을까?
물론 별다른 create index구문이 없다면 별도의 인덱스가 해당 테이블에 없다고 했으니,
위의 테이블에는 인덱스가 없다.
자, 하나하나의 의미와 왜 발생되었는지 확인해보자.
1. table scan
- 너무도 당연한거다. 데이터 search point도 없으며, 인덱스도 존재하지 않는다.
2. sort
- ORDER BY 절이 있으니까 SORT 작업이 이루지는건 당연한 걸까?
틀린말은 아니지만 맞는 말도 아니다. ORDER BY 절이 있기 때문이 아니라 clustered index가 없기 때문이 좀더 맞는 말이다.
참고로 DBMS 입장에서 sort작업은 엄청나게 high cost 가 발생되는 작업이다..
3. Parallelism
- 병렬처리를 했다는 뜻이다. 처리할 데이터가 많으니 데이터 페이지 단위 또는 옵티마이저가 적절하게 data range segment 작업을 하여 parallel scan을 한다는것이다.
이유가 그러면 테이블에 데이터 양이 많아서? 그럴수도 있고 아닐수도 있다.
절대적 데이터양 이 많으면 병렬처리로 갈 확률이 높은 것은 사실이다.
때에 따라서 데이터양 자체가 많은데 병렬처리를 하지 않는 경우도 있다.
여러가지 이유가 있겠지만 이런 경우에 많이 속한다.
1. 데이터양은 많지만 인덱스로 인하여 검색 데이터 양이 적어진 경우
2. 실제 물리적 데이터 양은 많으나, 통계정보의 업데이트가 이루어지지 않아서 옵티마이저가 데이터 양이 적다고 인식하는 경우
3. 실제로 데이터 양도 많고 통계정보에도 그렇게 표기되어 있지만 병렬처리후 merge 하는 비용이 더 크다고 옵티마이저가 판단하는 경우
이거모야? 정답도 없고 그때 그때 다르고 모이래? 라고 불만을 터트릴수 있지만 옵티마이저는 거짓말을 하거나 절대 자기 맘대로 하지 않는다.
특별히 role based 로 옵티마이저 세팅을 지정하지 않는다면 언제나 옵티 마이저는
Cost based로 움직인다. 정말이다. 비용을 항상 계산하고 거기에는 항상 논리적 계산과 분석을 한후에 옵티마이저가 실행계획을 리턴한다.
위의 내용이 어렵고 이해되지 않는다 해도 실망하지 말자. 나중에는 자연스럽게 이해 될것이다. 물론 이번강좌만으로는 한계가 있는건 사실이다.
자, 이제 그럼 엄청나게 비싼 비용이 드는 SORT작업을 DBMS로부터 덜게 해주어 전체적 속도를 향상 시켜보자.
..
지금 바로 몰 해야 한다 라고 머리속에 떠오른 사람은 굳이 이 강좌를 볼 필요가 없겠다.
자 생각이 안떠오른 사람은 다음 글을 계속 읽어주기 바란다.
자, 모르긴 몰라도 SORT를 제거하는게 이번 미션이다. 가장 좋은 방법은 몰까?
ORDER BY 절을 제거 하는 것? 맞는 말이다;;; 하지만 정렬이 안되잖아.
가장 좋고 강력한 방법은 바로 위에서 배웠던 CLUSTERED INDEX 생성이다.
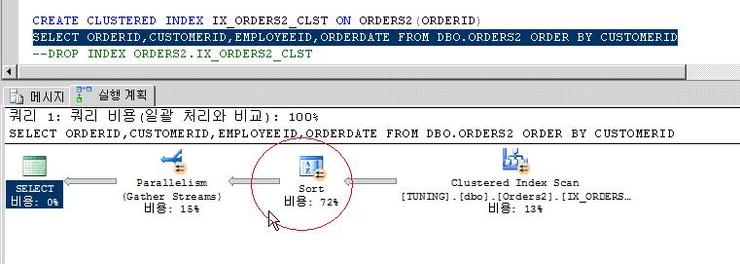
위의 문장을 실행해 보았다.
당당하게 CREATE CLUSTERED INDEX IX_ORDERS2_CLST ON ORDERS2(ORDERID)
를 치고 F5를 누른후 똑 같은 SELECT 절 SQL의 실행계획을 봤더니? 왠걸?
떡하니 아직도 SORT가 있다!!!
클러스터드 인덱스는 왠만하면 PK , 즉 유니크 한 컬럼이 좋다고 해서 ORDER테이블이니까 ORDERID 로 IDNEX컬럼으로지정까지 했는데 말이다!
이유는? 클러스터드 인덱스 컬럼과 ORDER BY 절의 컬럼의 불일치 때문이다.
반드시 클러스터드 인덱스가 있다고 해서 SORT가 없어지진 않는다!
이번에는 위에서 생성했던 클러스터드 인덱스는 그대로 두고 새롭게 NON CLUSTERED INDEX로 추가 생성하면서 CUSTOMERID 컬럼을INDEX컬럼으로 지정하였다.
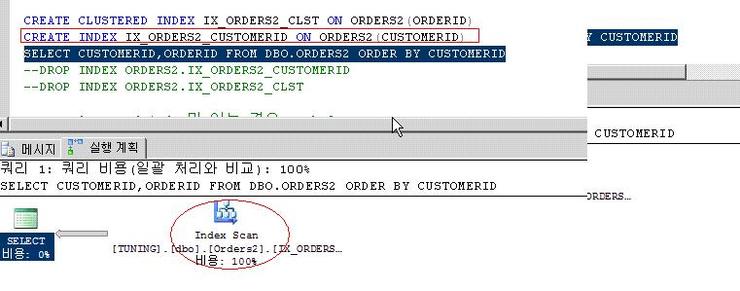
실행하였더니???? 와! SORT가 제거 되었네!
꼭 클러스터드 인덱스로 지정하지 않아도 SORT는 제거 되네? 맞는말이다.
하지만 INDEX SCAN 으로 수행되었다. SEEK 가 아니란 말이다.
그럼 index scan과 index seek 의 차이는?
최대한 복잡한 말 제거하고 단순하게 말하면 다음과 같다.
index Scan : 인덱스의 전체 또는 한 범위를 찾는것
index Seek : 인덱스의 특정범위의 행을 찾는 것
대체적으로 seek가 성능상 유리하다.
[2] The sequence decision Of Composite Index Columns.
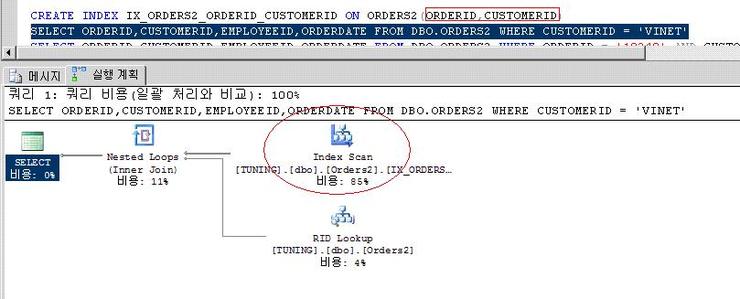
위의 쿼리처럼 ordered 컬럼과 customerid 컬럼 조합으로 복합 인덱스를 생성하고,
WHERE절에 customerid 컬럼으로 조회를 하였다.
분명히 복합 인덱스에 customerid컬럼도 포함하고 있어서 index seek로 될 것 같은데 index scan으로 되었다. 왜일까?
ORDER BY A , B
와 같은 쿼리절이 있을 때 어떻게 정렬이 되는가? 먼저 A 컬럼 그룹이 정렬되고 그 A그룹내에서 B 컬럼의 데이터가 정렬된다. 이와 비슷하게 복합인덱스도 그렇게 정렬이 된다고 보면 된다.
그렇기 때문에 순서가 뒤 순서인 customerid 만으로는 데이터를 찾는데 한계가 있으므로 index scan으로 쪽 찾는다고 보면 된다.
복합인덱스 생성시 순서가 중요하다 라는 사실이다.
이제 아래의 컬럼을 수행해보니 index seek가 된다.
이해가 될것이다.
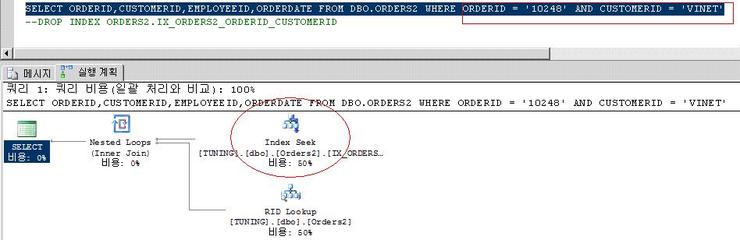
방금 수행한 where 절 에는 2개의 컬럼으로 찾지만 만약
SELECT ORDERID,CUSTOMERID,EMPLOYEEID,ORDERDATE FROM DBO.ORDERS2 WHERE CUSTOMERID = 'VINET'
와 같이 1개의 컬럼으로 찾는데 복합인덱스밖에 없고 customerid가 위에 처럼 2번째 순서로 지정되어 있다면 어떻게 해서 튜닝을 해야 할까?
복합인덱스 생성시 순서를 바꾸어 생성하는것도 방법이고, customerid 만을 위한 단일 인덱스를 생성하는것도 방법일것이다. 상황마다 다르기 때문에 정답은 없다.
그리고, 혹 이렇게 질문하는 똑똑한 독자도 있을것이다.
WHERE ORDERID = '10248' AND CUSTOMERID = 'VINET' 에서
WHERE CUSTOMERID = 'VINET' AND ORDERID = '10248'
로 쿼리를 변경하면 위에 처럼 index seek 로 수행이 되지 않는 것 아니냐? 그래서 SQL where절 기술할 때 순서도 중요하지 않느냐 라고 질문하실수 있다.
(복합인덱스 생성시 ORDERID,CUSTOMERID 순이었으므로)
아주 훌륭한 질문이다.
답은 몰까? 상황마다 다르다.
Optimizer type에 따라 달라진다.
rule based 였다면 where 절 기술 컬럼 순서가 중요하고, 그에 기반하여 실행계획이 수립된다.
만약 cost base였다면 where 절 에 기술하는 컬럼순서는 중요치 않다.
왜냐면? 비용기반으로 옵티마이저가 실행계획을 결정하기 때문이기도 하고, 바로 MS-SQL내부에서 SQL 절이 도착하면 내부적으로 수행되는 simplication 로 다시 SQL 이 조정되기 때문이다.( simplication 관련 참조 하시면 알수 있을것이다.)
또다른 독자는 이렇게 질문할수도 있겠다.
잘 모르겠고 모든 경우를 커버하려면 WHERE 절에 걸리는 모든 컬럼에 복합인덱스로 생성하면 되지 않느냐? 라고 반문할수도 있다.
절대 무작정 만드는 인덱스는 silver bullet이 아니다.
특히나, 복합 인덱스의 경우에는 상호 컬럼 index page depth가 지속적으로 늘어나 index seek 나 scan시 과도한 cost를 불러일으켜 조회 성능에 저하를 초래 한다.
또한 절대적인 디스크 용량 차지도 물론 많아 지게 되는건 당연한 사실.
[3] Corvering Index
Corvering Index 란 Composite index에 Query검색에 필요 한 모든 Column들이 포함되는 특별한 NonClustered Index 의 형태로 index 만으로 데이터를 조회하는 특징을 지닌다.
복합 인덱스를 만들고 아래 쿼리를 수행해 보자.
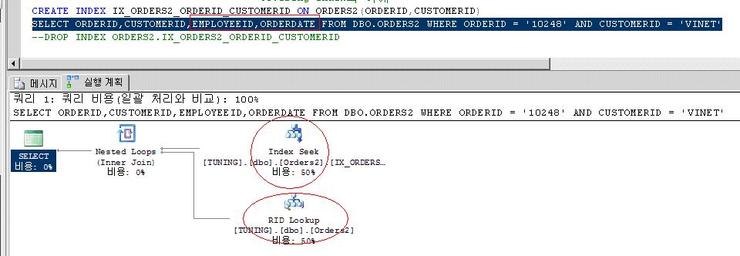
Index seek로 where절 조회 자체에 대한 부분은 올바르게 수행된 것 같다.
그런데 난데 없이 RID LOOKUP이 발생하였다.
RID Lookup 은 몰까?
RID Lookup 외에 SQL 2005 이전에서는 Bookmark Lookup 이라는게 있었다.
또한 클러스터드 인덱스가 존재할때는 key lookup형태로 바뀌어 표기된다(그 이유는 클러스터드 인덱스 생성시 각 컬럼에 클러스터드ID값을 참조하게 됨으로써 lookup 대상이 바뀌는 특성 때문인데 이는 이해하기에는 별도의 클러스터드 인덱스 강좌를 해야할 정도의 수준으므로 생략하겠다)
어쨌든 Lookup 이녀석의 주요 골자는 이렇다.
SELECT 하려는 컬럼이 인덱스에 없을경우 non-clustered index key값을 가지고 Heap Page(혹은 clustered index 가 있는 테이블일 경우에는 clustered index를) 검색하는것을 의미한다.
그러므로 당연히 Heap 이나 clustered index 를 찾아가는 과정에서 추가적인 I/O cost가 증가한다.
Oracle로 예를들면 인덱스 영역에 저장되어있는 ROWID를 가지고 Data Block Access 와 흡사하다고 생각하면 된다.
이러한 배경으로 인하여, 당연히 SELECT하는 컬럼이 모두 인덱스에 존재하고 인덱스가 데이터 조회에 관련된 모든 사항을 corver 하여 최적의 데이터 조회 성능을 낼 때,
이를 Covered Index 라고 하는것이다.
당연히 Covered index 만으로 조회 될때는 별도의 RID Lookup은 발생하지 않는다.
.
자, 아래와 같은 경우에는 SELECT 절에 나오는 컬럼을 모두 복합인덱스로 설정한 것이다.
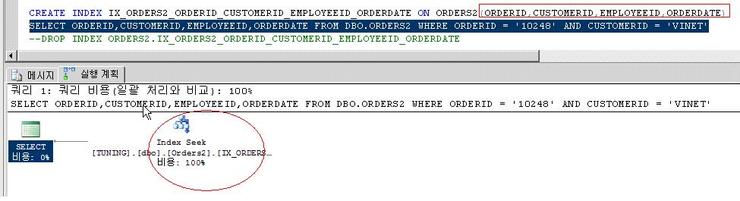
당연히 RID Lookup은 발생하지 않는다.
하지만 이게 최적의 솔루션이 아니라는 것을 독자분들은 이미 알고 있다.
[INCLUDE 키워드를 활용]

INCLUDE는 SQL2005 부터 지원한다.
그리고 non-clustered index에만 생성해야 한다.
그리고 Index page depth가 깊어지거나 추가되는 것이 아닌, Leaf level 바로 하위에 데이터 정렬이 이루어진다.
그리하여 위의 실행계획에서는 lookup이 발생되지 않는다.
[4] Search Arguments with Index
SARG | Non-SARG |
WHERE name = ‘DEV.WON’ | WHERE name = member_mane |
WHERE age < 30 | WHERE age != 30 |
WHERE price = 100/12 | WHERE price *12 = 100 |
WHERE name like ‘D%’ | WHERE substring(name , 1, 1) = ‘D’ |
WHERE price between 9 AND 20 | WHERE price < 2 AND price > 4 |
WHERE name like ‘DONG%’ | WHERE name like ‘%DONG’ |
위의 표를 보면 바로 어떤걸 의미하는것인지 알수 있다.
즉, 왼쪽편의 SQL 문장과 같이.
데이터 검색 범위를 좁히고 되도록 이면 INDEX를 사용할수 있는 쿼리 문장을 사용하라는 뜻이다.
[5] Index Management
[5-1] DBCC CONTIG
자, 이제 인덱스 관련된 관리를 통하여 튜닝을 해보자.
먼저 테이블의 데이터 현황과 인덱스에 대한 단편화가 어떻게 되어 있는지 살펴볼수 있어야 한다.
자, 아래의 명령을 실행해보니 아주 잘 결과를 표현해 준다.
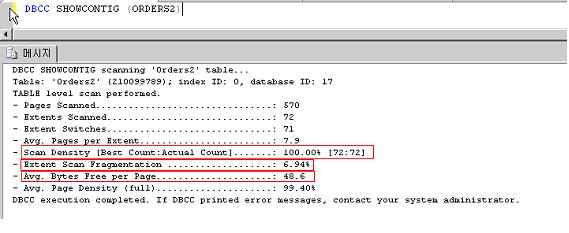
빨간 네모를 친부분을 중점적으로 보았으면 한다.
첫번째 빨간 네모 항목은 바로 검색밀도다 [최적 : 실제] 대비를 나타내고 있고 100%에 가까울수록 검색 밀도가 높아 좋은 상태를 의미한다.
두번째 빨간 네모 항목은 논리 검색 조각화 상태다. 0%에 가까울수록 조각화가 없는 좋은 상태다.
세번째 빨간 네모 항목은 익스텐트 검색 조각화 상태다.(익스텐트 내 빈공간 비율을 의미) 마찬가지로 0%에 가까울수록 좋다.
아래와 같이 table.. index단위로도 조회 가능하다.
명령어 예)
DBCC SHOWCONTIG (Table)
DBCC SHOWCONTIG (Table, Index)
DBCC SHOWCONTIG (Table) WITH FAST
그리고 아래표는 각각의 항목과 설명을 나타내고 있다.
항목 | 설명 |
스캔한 페이지 | 1페이지 = 8KB 이므로 스캔한 페이지는 800KB |
스캔한 익스텐트 | 익스텐트 = 1페이지 * 8 이므로 17 * 8KB * 8 = 1088 KB |
전환된 익스텐트 | 익스텐트를 스캔하면서 익스텐트와 익스텐트 사이를 옮겨간 횟수를 의미. |
익스텐트 당 평균 페이지 수 | 하나의 익스텐트는 8개의 페이지라고 볼 수 있는데 익스텐트가 조각나서 하나의 익스텐트에 평균 5.9개의 페이지가 있는 것 |
스캔밀도 | 스캔밀도가 100% 이면 조각난 상태가 아니며 100% 미만이면 그 만큼 조각난 상태. 그러므로 위의 경우 약 25%가 조각난 상태라고 볼 수 있다.| |
논리 스캔 조각화 상태 | 논리적인 조각화 상태를 의미합니다. 삽입, 갱신 등의 DML문에 의해서 인덱스의 트리구조가 전환된 것을 의미. |
익스텐트 스캔 조각화 상태 | 인덱스의 잎 페이지 스캔에서 순서가 바뀐 익스텐트의 비율. |
페이지 당 사용 가능한 평균 바이트 수 | 하나의 페이지는 최대 8060바이트가 저장될 수 있다. 이것은 페이지들이 사용할 수 있는 가용 페이지의 공간을 의미. |
평균 페이지 밀도(전체) | 스캔한 페이지의 조각화 상태. 100%이면 조각난 상태가 아니며, 100% 미만이면 조각난 상태. |
모든 튜닝의 시작은 정확한 상황 파악과 진단이다.
현상을 파악을 해야 튜닝의 계획이 잡히는 법이다.
[5-2] INDEX DROP&CREATE / DBREINDEX / INDEXDEFLAG
경우에 따라서는 INDEX를 drop하고 새로 create 하는 방식을 쓴다. 다음과 같은 경우에 대표적이다.
1. 기존 과 신규 인덱스의 이름이 동일하게 사용될 경우
2. NonClustered Index를 Clustered Index로 만들경우
(clustered Key ID 참조 재정렬로 인한 성능이슈 방지를 위하여)
DBCC DBREINDEX ([table_name] , [‘index_name’ ])
e 사용이유 : 해당테이블에 많은 트렌젝션(CUD) 발생이 되면 테이블 단편화 가 가속되어 검색 밀도가 떨어져 인덱스 검색에 의한 성능향상이 감소된다. 이 때문에 단편화된 인덱스의 조각화 상태를 낮추어 검색성능을 높인다.
(하지만 대용량 테이블의 경우 주의 해야 합니다. 데이터도 많고 넌클러스터드로 많은 인덱스가 걸려있다면 Re buiding되면서 폭발적 로그 증가로 인하여 disk full 등의 risk 가 발생할수 있습니다.
따라서 로그 의 폭발적 증가를 막기 위해서는 SELECT databasepropertyex(‘sampleDB’ , ‘recovery’)
를 통해 나온 값이 full 이라면 simple recovery mode로 변경해 주셔야 합니다.
Alter database sampleDB set recovery simple)
대용량 데이터 베이스의 경우 index rebuild 를 online 상태에서 함부로 했다간 난리 납니다.
DBCC INDEXDEFLAG ( db이름, table이름, index이름)
e 인덱스 스캔성능을 향상 시키기 위한 목적으로 페이지의 물리적 순서가 왼쪽에서 오른쪽에로 잎 노드의 논리적 순서와 일치하도록 인덱스 잎 수준의 조각을 모은다.
e DBCC INDEXDEFLAG 는 온라인 상태에서도 가능. 이 작업은 lock cycle 이 짧으므로 실행중인 쿼리나 업데이트 lock를 차단하지 않는다.
e 진행도중 언제든지 종료할수 있으며 종료된 시점까지의 상태를 보존한다.
DBREINDEX 와 INDEXDEFLAG 의 비교
| DBREINDEX | INDEXDEFLAG |
구축시간 | 일정 | 조각화에 따라 다름 |
온라인서비스 운영 | 2005 부터 가능(제약 많음) | 가능 |
효과 | 100% | 상황에 따라 다름 |
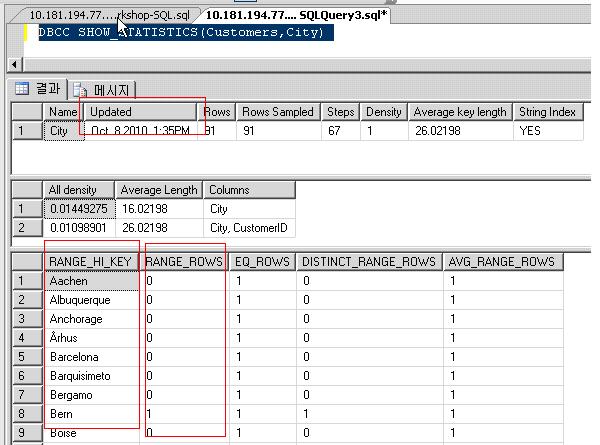
마지막으로 인덱스 통계 명령어를 통해서 마지막 통계 업데이트 시간을 알수 있고 그 시간을 통해 적절하게 통계에 대한 재 생성의 여부를 결정할수 있다.
DBCC SHOW_STATISTICS(테이블명,인덱스명)
쿼리힌트)
쿼리 힌트에 대한 나열과 설명은 의미가 없을 것 같다.
그리고 필자는 정말 쿼리 힌트는 특수한 경우가 아니라면 쓰지 말라고 권장하고 싶다. 어차피 쿼리 힌트를 써서 옵티마이저가 선택한 실행계획보다 더 좋은 성능을 내는 경우가 그렇게 많지 않고 대부분 옵티마이저가 정한 실행계획이 올바른 경우가 많다.
(다만, 통계 상황이 최신으로 업데이트 되어 있어서 옵티마이저가 적절한 통계를 토대로 실행계획을 수집 한다는 전제가 있다!)
특수한 경우가 아니라면, 쿼리 힌트를 통한 튜닝보다는 인덱스 단편화 관리를 잘하고 통계 수집을 원활히 하고, 적적한 인덱스 수립을 하는 것이 훨씬 효과적이고 정석적인 방법이라 생각한다.
그리고 쿼리 힌트는 그때 당시에는 적절한 힌트를 썼을 지어도 시간이 지나 데이터양의 변화가 심해 졌을 경우에는 작성했던 쿼리 힌트가 올바르지 않을수 있다. 다시 작성하고 소스를 수정해야 하는 경우가 오지 않는다는 보장이 없다.
SQL 쿼리 튜닝)
이제 인덱스는 다소 지겨우니 SQL 쿼리 문장 자체를 튜닝해보자.
사실 개발 시간의 부족과, DB 쿼리 에 대한 이해 부족도 등으로 인하여 잘못된 쿼리 SQL 문장이 작성되는 것이 사실이다. 그러지 않도록 노력하고 방안을 찾아야 함은 개발자와 DBA 모두의 과제가 아닌가 생각이 든다.
단순하고 심플한 SQL 문장으로 튜닝해 보자.
--쿼리튜닝예제1
SELECT A.customerID ,
(
SELECT SUM(quantity)
FROM [OrderDetail2] B
WHERE
A.orderid = B.orderid
) qty
FROM orders A
위의 SQL 문장을 보자.
Order 테이블과 orderDetail2 테이블은 서로 1:N의 관계를 가지고 있으며,
하나의 주문에 대한 상세 주문정보(예를들면 주문한 상품들) 의 관계를 가지고 있다.
하나의 주문에 대해서 주문한 상품등의 카운트를 구하기 위하여 위와 유사한 쿼리를 많이 수행하곤 한다.
하지만 무엇이 문제일까? 사실 orderDetail 테이블에 데이터 양이 많지 않으면 그다지 문제가 되지 않는다.
하지만 데이터양이 많아질수록 order 테이블 레코드 하나당 orderDetail테이블의 sum집계 연산 COST는 기하급수적으로 늘어날것이다.
이러한 문제성있는 쿼리에 대해서 다음과 같이 튜닝해 보았다.
SELECT A.customerID , B.qty
FROM orders A LEFT OUTER JOIN
(
SELECT orderid , SUM(quantity) AS qty
FROM [OrderDetail2]
GROUP BY orderid
) B
ON A.orderid = B.orderid
위의 SQL 문장을 보도록 하자.
Group by 를 먼저 하여 SUM 값을 가져온후 join을 하고 있다. 어떤 효과가 발생하는지는 직접 독자들이 실행하여 보길 바란다.
다음은 흔하게 쓰곤 하는 OR 절에 대한 부분이다.
아래와 같은 SQL문장은 매우 흔하게 사용한다.
하지만 OR 절은 내부적으로 Table Full Scan을 자주 유발시키는 주범이다.
OR 절로 걸려야 하기 때문에 Data Scan 범위가 넓다는것이다.
SELECT * FROM dbo.OrderDetail2
WHERE productId = 11 or quantity >3
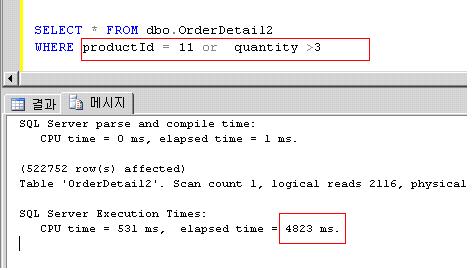

위의 실행결과 약 4.8초 가 소요되었으며, 예상대로 Table scan이 이루어졌다.
아래와 같이 쿼리를 수정해 보았다. 물론 결과물은 동일하다.
SELECT * FROM dbo.OrderDetail2
WHERE productId = 11
UNION
SELECT * FROM dbo.OrderDetail2
WHERE quantity >3
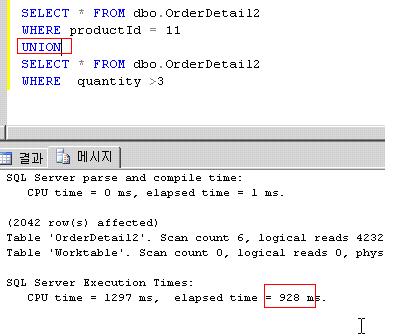
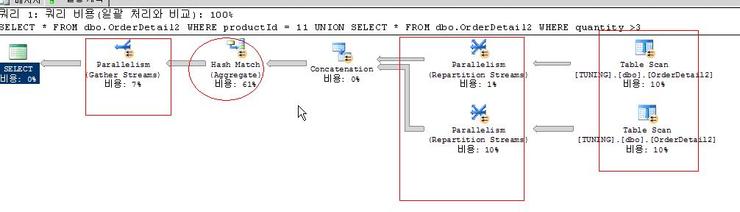
수행해본 결과 0.9초가 걸렸다. 여전히 튜닝해야 할 포인트가 많지만 SQL 문장만 바꾸었을 뿐인데 현격히 속도가 빨라졌음을 알수 있다.
또한 눈여겨 볼점은 병렬처리를 수행하여 속도가 빨라졌다는 점이다.
그외에도 SQL 문장이 DB로 하여금 무리하고 과도한 연산을 수행하게 하는 비효율적인 경우는 많다.
그 모든 것들을 나열하기에는 너무 많으며 때에 따라서는 어떤것도 정답이 될수 있고, 틀린것이 될수 있기 때문에 단언할 수는 없다.
Join 의 비밀)
사실 Oracle에서 얘기하는 Driving 테이블을 SQL서버에서는 OUTER테이블이라고 칭한다.
본강좌에서는 모두 통일하여 Driving 테이블이라 칭하겠다.
1. NESTED LOOP JOIN의 특징
① 순차적 : Driving Table의 처리범위에 있는 각각의 로우들이 순차적으로 수행될 뿐 아니라
테이블간의 연결도 순차적이다.
② 선행적 : 먼저 액세스되는 테이블의 처리범위에 의해 처리량이 결정.
③ 종속적 : 나중에 처리되는 테이블은 앞서 처리된 값을 받아 액세스.
즉 값을 받아서 처리범위가 결정됨
④ Random Access : Driving Table의 인덱스 액세스는 첫번째 로우만 Random Access이고,
나머지는 Scan, 연결작업은 Random Access .
⑤ 선택적 : 연결되는 방향에 따라 사용되는 인덱스들이 달라질 수 있다.
⑥ 연결고리중요, 방향성 : 연결고리의 인덱스 유무에 따라 액세스 방향 및 수행속도에 많은 차이가
있음.
⑦ 부분범위처리 가능 : 연결작업 수행 후 Check 되는 조건으로 부분범위처리를 하는 경우에는
조건의 범위가 넓거나 없다면 오히려 빨라짐
2. NESTED LOOP JOIN의 사용
① 부분범위처리를 하는 경우
- Nested Loop Join은 주로 전체가 아닌 부분범위를 처리하는 경우에 유리.
② Join 되는 테이블이 상호의존적인 경우
- Join 되는 어느 한 쪽이 상대방 테이블에서 추출된 결과를 받아야 처리범위를 줄일 수 있는
상태라면 항상 유리. 하지만, Driving Table의 처리가 많거나 연결 테이블의
Random Access 량이 많을 경우에는 Sort/Merge Join 보다 불리.
③ 처리량이 적은 경우
- Random Access를 많이 하므로 On-Line 애플리케이션처럼 처리량이 적은 경우에 유리.
④ Driving Table 의 선택이 관건
- 어느 테이블이 먼저 ACCESS 되는가가 수행속도에 큰 영향을 미치게 된다..
3. SORT MERGE JOIN의 특징
① 동시적 : 각각의 테이블이 자신의 처리범위를 액세스하여 정렬해 둔다.
② 독립적 : 각 테이블은 다른 테이블에서 어떠한 상수값도 제공 받지 않고 주어진 상수값에 의해서만
범위를 줄인다.
③ 전체범위처리 : 부분범위처리를 할 수 없다./3
④ Scan방식 : 자신의 처리범위를 줄이기 위해 인덱스를 사용하는 경우만 Random Access이고,
Merge작업은 Scan
⑤ 선택적 : 연결고리가 되는 칼럼은 인덱스를 사용하지 않는다..
⑥ 무방향성 : Join의 방향과는 무관.
4. SORT MERGE JOIN의 사용
① 전체범위처리를 하는 경우
- Sort/Merge Join은 주로 부분이 아닌 전체범위를 처리하는 경우에 유리.
② EQUI-JOIN에서만 가능
③ Join되는 테이블이 상호독립적인 경우
- 상대방 테이블에서 어떤 상수값을 받지 않고도 처리범위를 줄일 수 있는 상태에서 유리.
상수값을 받아 줄여진 범위가 30%이상이면 Sort/Merge Join이 유리.
④ 처리량이 많은 경우
- Random Access를 하지 않으므로 전체범위처리에 유리.
⑤ 효과적인 인덱스 구성이 관건
- 자신의 처리범위를 어떻게 줄이느냐가 관건이므로 효과적인 인덱스구성이 매우 중요
5 HASH JOIN의 특징
① 독립적 : 각 테이블은 다른 테이블에서 어떠한 상수값도 제공 받지 않고 주어진 상수값에 의해서만
범위를 줄인다.
② 전체범위처리 : 부분범위처리를 할 수 없다.
③ 선택적 : 연결고리가 되는 칼럼은 인덱스를 사용하지 않는다.
④ SORT 안함 : SORT를 하지 않으므로 SORT MERGE JOIN 보다 좋은 성능을 내며,
작은 table 과 큰 table 의 join시에 유리.
6. HASH JOIN의 사용
① 전체범위처리를 하는 경우
- HASH Join은 주로 부분이 아닌 전체범위를 처리하는 경우에 유리.
② EQUI-JOIN에서만 가능
③ 처리량이 많은 경우
- Random Access를 하지 않으므로 전체범위처리에 유리.
④ 효과적인 인덱스 구성이 관건
- 자신의 처리범위를 어떻게 줄이느냐가 관건이므로 효과적인 인덱스 구성이 매우 중요.
⑤ 작은 table 과 큰 table의 join시에 유리.__
튜닝에 유용한 것들)
튜닝을 하기 전에 가장 필요한 것은 무엇일까?
바로 현재 시스템에 어떤 문제가 있는지 어떤 것을 튜닝해야 할지 알아야 하는것이다.
이것은 마치 의사가 진찰 하기전에 정확하게 문진하고 어디가 아픈지를 알아야 다음 치료로 가기 위한 시간절약과 방향을 잡을수 있을것이다.
[의사에겐 청진기, DBA에겐 모니터링 툴]
PSSDiag – user 가 요청한 SQL 문장 수집.file로 save되며 시스템 부하가 profiler 보단 적다.
SQLDiag – SQL 2005부터 기본적으로 설치되어있다.
아래는 SQLDiag실행화면
SQLNexus – 유명한 Ken Handerson 가 남기고간 위대한 무료 툴. Trace파일 분석을 해주는 아주 유용한 툴이다.
자 다음은 각종 유용한 SQL 문장을 소개 한다.
[1] 사용하지 않는 인덱스를 찾아라
위에서도 언급했지만 무분별한 인덱스 생성은 결코 좋지 못하다. 사용하지 않은 인덱스를 추출하여 정리해 보자. 이를 위해서 아래의 쿼리를 공유하니 유용하게 사용하길 바란다.
---------------------------------------------------사용하지않은인덱스추출
------초기테이블생성
use master
go
DECLARE @curdb varchar(50)
set @curdb = 'master'
select @curdb as DBName, object_name(i.object_id) AS TAB, i.name AS IDXName into #unusedindex
from sys.indexes i, sys.objects o
where i.index_id NOT IN (
select s.index_id from sys.dm_db_index_usage_stats s
where s.object_id=i.object_id and i.index_id=s.index_id
and database_id = db_id(@curdb)
)
and o.type = 'U' and o.object_id = i.object_id
order by object_name(i.object_id) asc
go
------생성DB 확인
--select name from sys.sysdatabases
------사용하지않은인덱스추출
DECLARE @curdb varchar(50)
set @curdb = 'DBName'
INSERT INTO #unusedindex(DBName, TAB, IDXName)
select @curdb as DBName, object_name(i.object_id) AS TAB, i.name AS IDXName
from sys.indexes i, sys.objects o
where i.index_id NOT IN (
select s.index_id from sys.dm_db_index_usage_stats s
where s.object_id=i.object_id and i.index_id=s.index_id
and database_id = db_id(@curdb)
)
and o.type = 'U' and o.object_id = i.object_id
order by object_name(i.object_id) asc
go
------결과조회
select * from #unusedindex
drop table #unusedindex
[2] 이 인덱스는 어디 테이블에 있고 이 테이블은 어디 DB에 있는겨
또 필요한 것이 있다. 바로 인덱스->테이블->DB 순으로 서로 object들을 찾는것이다.
----------------------------------------------------------------------------Show_InDEX 정보출력
Use master
go
SET NOCOUNT ON
CREATE TABLE #ShowIndexInfo (DBNAME VARCHAR(50), TableName VARCHAR (255),IndexName VARCHAR (255), IndexDesc VARCHAR(200), INDEXKEY VARCHAR(400) )
go
CREATE Proc sp_ShowIndex @CURDB VARCHAR(50)
AS
SET NOCOUNT ON
DECLARE @tablename VARCHAR(255)
CREATE TABLE #ShowIndexInfo2 (TableName VARCHAR(255),IndexName VARCHAR(255), IndexDesc VARCHAR(200), INDEXKEY VARCHAR(400))
CREATE TABLE #ShowIndexInfo3 (IndexName VARCHAR (255), IndexDesc VARCHAR(200), INDEXKEY VARCHAR(400))
DECLARE tables CURSOR READ_ONLY FOR SELECT Schema_Name(uid)+'.'+[Name] FROM SYS.SysObjects WHERE TYPE = 'U'
OPEN tables FETCH NEXT FROM tables INTO @tablename
WHILE @@FETCH_STATUS = 0
BEGIN
INSERT INTO #ShowIndexInfo3 (IndexName, IndexDesc , INDEXKEY )
EXEC ('sp_helpindex ''' + @tablename + '''')
INSERT INTO #ShowIndexInfo2( TableName ,IndexName , IndexDesc, INDEXKEY )
SELECT @tablename,* from #ShowIndexInfo3
DELETE FROM #ShowIndexInfo3
FETCH NEXT FROM tables INTO @tablename
END
INSERT INTO #ShowIndexInfo (DBNAME , TableName,IndexName, IndexDesc, INDEXKEY)
SELECT A.DBNAME,B.* FROM (SELECT @CURDB AS DBNAME) A , #ShowIndexInfo2 B
DROP TABLE #ShowIndexInfo2
DROP TABLE #ShowIndexInfo3
CLOSE tables
DEALLOCATE tables
GO
declare @name varchar(100), @cmd varchar(2000)
DECLARE dbname CURSOR READ_ONLY FOR SELECT Name FROM SYS.sysdatabases where name notin('master','msdb','model','tempdb','pubs','northwind','DISTRIBUTE','SQLBPA')
OPEN dbname FETCH NEXT FROM dbname INTO @name
WHILE @@FETCH_STATUS = 0
BEGIN
select @cmd = N'use ' + quotename(@name) + N' exec sp_ShowIndex '+@NAME
exec (@cmd)
FETCH NEXT FROM dbname INTO @name
END
CLOSE dbname
DEALLOCATE dbname
select * from #ShowIndexInfo
drop table #ShowIndexInfo
drop proc sp_ShowIndex
SET NOCOUNT OFF
GO
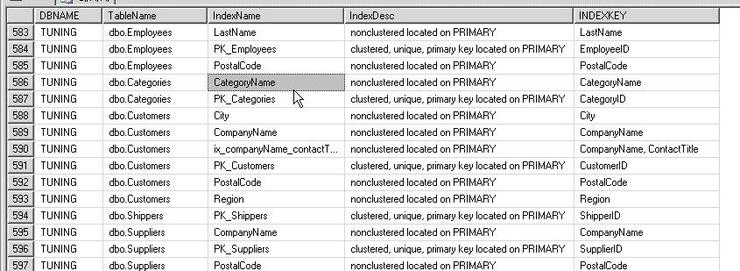
[3] 테이블을 자세히 보라
중요한 테이블의 정보에 대해서 면밀히 살펴볼 필요가 있다.
------------------------------------------------------------------------ 테이블사용량정보
USE MASTER
GO
SET NOCOUNT ON
CREATE TABLE #tblSpace( DBNAME VARCHAR(50), name VARCHAR(50), rows INT,reserved VARCHAR(30),data VARCHAR(30), index_size VARCHAR(30),unused VARCHAR(30))
GO
CREATE PROC SP_TABLERECINFO @CURDB VARCHAR(100)
AS
DECLARE RCur CURSOR READ_ONLY FOR select 'sp_spaceused ''' + SCHEMA_NAME(uid)+'.'+NAME + '''' AS SQL from SYSOBJECTS where XTYPE = 'U'
DECLARE @strSQL VARCHAR(2000), @dtStart DATETIME
OPEN RCur FETCH NEXT FROM RCur INTO @strSQL
CREATE TABLE #tblSpace2( name VARCHAR(50), rows VARCHAR(30),reserved VARCHAR(30),data VARCHAR(30),index_size VARCHAR(30),unused VARCHAR(30))
WHILE (@@fetch_status <> -1)
BEGIN
IF (@@fetch_status <> -2)
BEGIN
INSERT INTO #tblSpace2
EXEC(@STRSQL)
END
FETCH NEXT FROM RCur INTO @strSQL
END
insert into #tblSpace(DBNAME,[name], [rows], reserved, data, index_size, unused)
SELECT A.DBNAME,B.* FROM (SELECT @CURDB AS DBNAME) A ,#TBLSPACE2 B
DROP TABLE #TBLSPACE2
CLOSE RCur
DEALLOCATE RCur
GO
declare @name varchar(100), @cmd varchar(2000)
DECLARE dbname CURSOR READ_ONLY FOR SELECT Name FROM master.dbo.sysdatabases where name notin('master','msdb','model','tempdb','pubs','northwind')
OPEN dbname FETCH NEXT FROM dbname INTO @name
WHILE @@FETCH_STATUS = 0
BEGIN
select @cmd = N'use ' + quotename(@name) + N' exec SP_TABLERECINFO ' +@NAME
exec (@cmd)
FETCH NEXT FROM dbname INTO @name
END
CLOSE dbname
DEALLOCATE dbname
GO
SELECT * FROM #tblSpace ORDER BY DBNAME, ROWS DESC
DROP TABLE #tblSpace
DROP PROC SP_TABLERECINFO
SET NOCOUNT OFF
GO
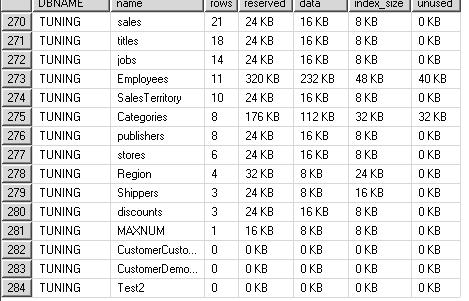
마무리하며)
정말 정신없이 튜닝에 대해서 정리해 보았다.
아직 다루지 않은것들이 너무 많다.
l 2개이상의 JOIN 쿼리에서의 인덱스 설정 및 구성
l 트렌젝션처리 방식을 이용한 튜닝
l 커서를 사용함으로써 발생된 이슈에 대한 튜닝
l 시스템 구성을 최적화하여 성능을 높이는 시스템 레벨 튜닝
너무 방대하고 상황마다 다르지만 끝으로 몇가지 를 권장한다.
1. 인덱스와 통계 자료에 대해서 주기적으로 업데이트하라.
- 이는 매우 중요하다. 옵티마이저에게 최신의 자료를 제공해야 할 DBA의 의무가 있다.
2. AdHoc 쿼리를 지양하라. Trivial PLAN 을 갖을수 있도록 Prepared 타입의 SQL 로 작성하라.
- 사실 AdHoc 쿼리도 빈번한 수행 쿼리에 대해서는 proccache에 저장된다 하지만 where 절의 key값만 다르게 해서 다양한 Adhoc 쿼리가 수행요청이 온다면 proccache 에는 무수히 많은 complied plan이 쌓여 메모리 누수가 발생할수 있다. 매우 중요하다.
3. 적절한 인덱스를 구성하라.
- 너무 무분별하지 않게, 정확하게 필요한 인덱스를 만들어라
4. 항상 문제가 되는 SQL 쿼리가 있는지 모니터링하고 지속적으로 튜닝하라.
- 처음에는 별게 아닌 것 같지만 나중에 큰산이 되어 시스템을 망가트리게 될수 있다. 지속적인 관심과 튜닝은 필수다.
모 이정도로 본 강좌를 정리하려 한다.
회사다니며, 틈틈히 본 강좌를 작성하였으나, 역시 시간과 여유의 문제가 따른다. 좀더 완성도 있고 좋은 내용으로 구성하고 싶었으나, ㅜ
어쩌랴.. 지금 상황에서 최선을 다한것에 만족하려 한다.
끝으로)
부족한 강좌 끝까지 봐주셔서 감사드립니다. 편의상 짧은 어투도 양해부탁드려요.
욕심에는 Oracle과 비교하며 작성하려 했으나 너무 여의치 않네요. 튜닝은 결코 만만하거나 섣부르게 할수 있는 부분이 아닙니다. 정확히 알고 이해하고 있어야만 가능하지죠. 하지만 모든지 노력하고 연습하면 가능하겠죠? 저도 그러기 위해서 노력하렵니다..
대부분 자동차 튜닝의 끝을 본 사람들이 이런 얘기를 한다고 하죠. 자동차의 튜닝의 끝은 순정 부품이다.
저는 DB튜닝의 끝을 감히 이렇게 말씀 드리고 싶습니다.
“DB튜닝의 끝은 DB Modeling에 있다.”
이 말은 속도를 빠르게 하기 위해서 다시 DB모델링을 한다는게 아니고요 DB모델링이 처음부터 잘되어있으면 상당수의 많은 속도 이슈가 제거될수 있다는 뜻입니다.^^;
어쨌든 긴 강좌 봐주셔서 감사합니다.
다음에 또 뵈요.~~






























 WMICodeCreator.zip
WMICodeCreator.zip mysql-5.1.73.z01
mysql-5.1.73.z01